#encoding:utf-8 #编码设定,为了输出中文,python2.7 print中文和raw_input 中文,显示乱码
import urllib2 # 需要urllib2 包
import urllib #需要urllib 包
import re #需要re正则包
data = raw_input(“请输入域名:\n”.decode(‘utf-8’).encode(‘gbk’)) #输入域名
print (“结果如下:”.decode(“utf-8”).encode(‘gbk’)) #提示一下内容为结果
url = “http://s.tool.chinaz.com” # 获取爱站的信息
urldata = url + “/same?s=” + data + “&page=1″ #把输入的域名带入到get请求中,通过爱站获取信息
request = urllib2.Request(urldata) #发送get请求
response = urllib2.urlopen(request) #获取get请求的响应数据
page = response.read() #读取get请求的响应数据保存到page变量中,以便后面调用
pattern = re.compile(‘w30-0 overhid.*?<a href=\’http:\/\/(.*?)\’ target=.*?</a>’)
#编写正则,匹配get请求响应数据的正则,圆括号部分表示要被输出的.*? 的正则表示任意字符匹配N次,输出子域名
patternip = re.compile(‘col-blue02 fwnone fl mr15.*?class=”col-red pr10”>(.*?)\[.*?/a></span>’)
#编写正则,匹配get请求响应数据的正则,圆括号部分表示要被输出的.*? 的正则表示任意字符匹配N次,输出IP。
results = re.findall(pattern,page) #从get请求的响应数据中,把经过正则过滤掉的数据找出来,并保存到results变量中。
resultsips = re.findall(patternip,page) #从get请求的响应数据中,把经过正则过滤掉的数据找出来,并保存到resultsips变量中。
print (“IP地址:”.decode(“utf-8”).encode(‘gbk’)) #输出提示信息
for resultsip in range(0,len(resultsips)): #输出获取到的IP
print resultsip,resultsips[resultsip]
print (“子域名:”.decode(“utf-8”).encode(‘gbk’)) #输出提示信息
for result in range(0,len(results)): #输出获取到的子域名
print result,results[result]
正则表达式使用说明:
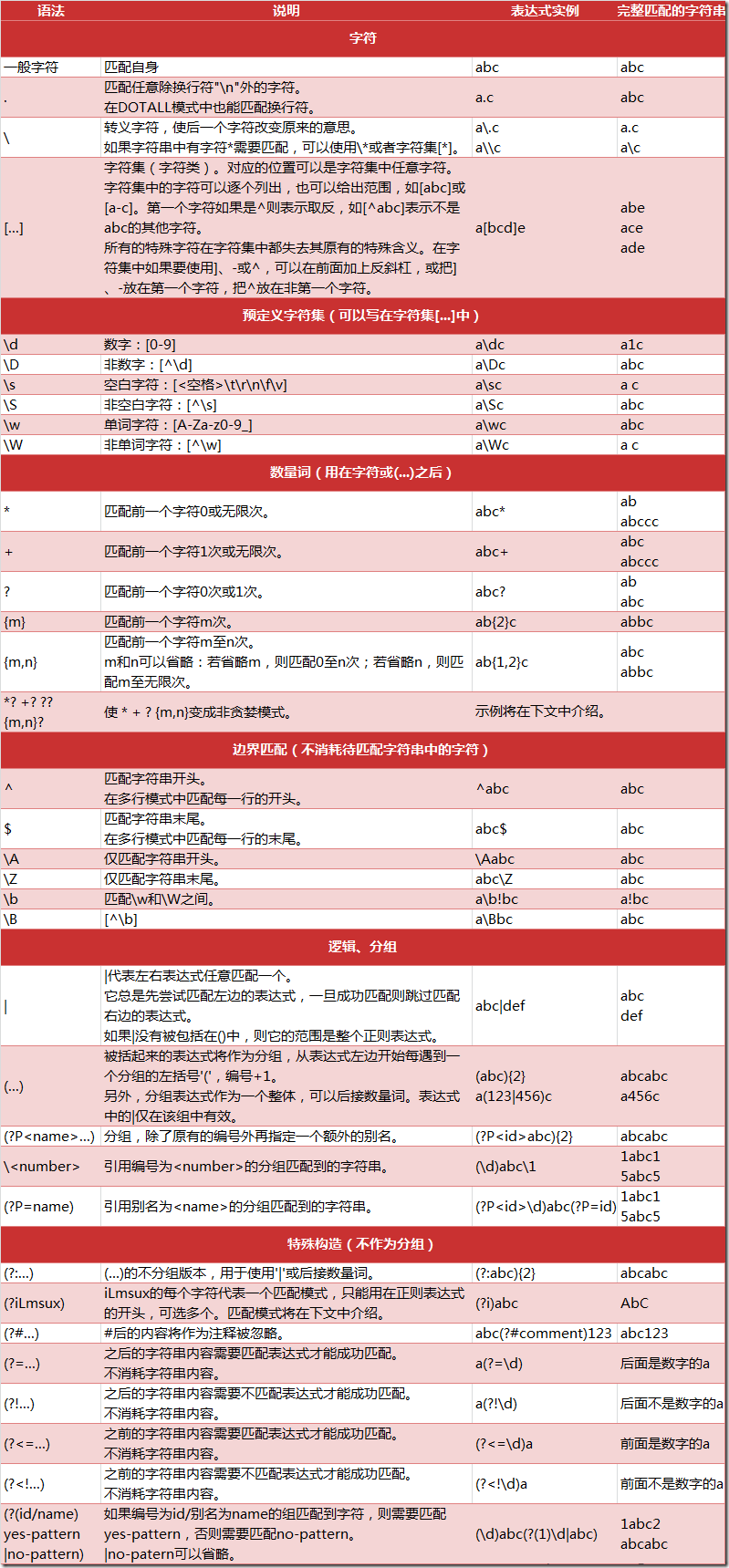
正则